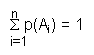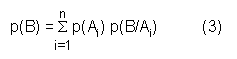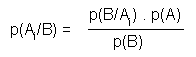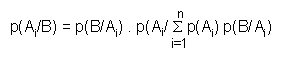GUÍA TÉCNICA: Métodos cuantitativos para el análisis de riesgos
![]()
GUÍA TÉCNICA: Métodos cuantitativos para el análisis de riesgos |
|
|
|
2 MÉTODOS PARA LA DETERMINACIÓN DE FRECUENCIAS |
||||||
|
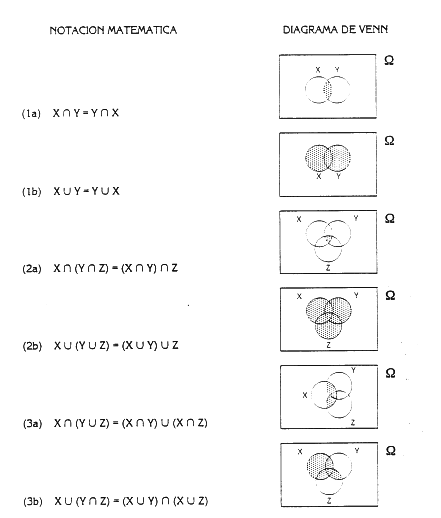
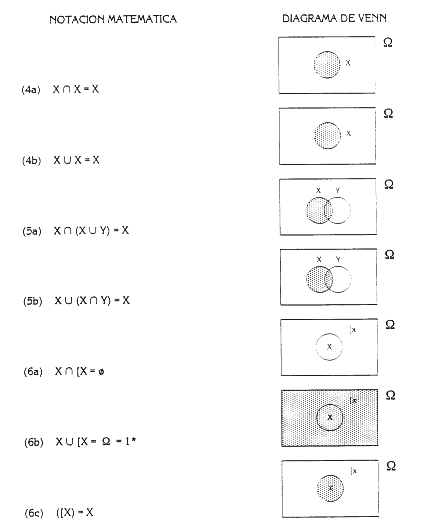
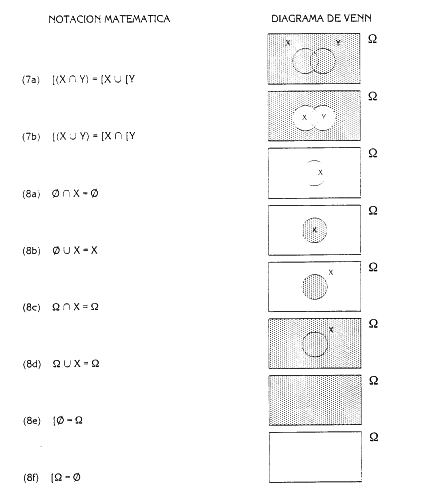
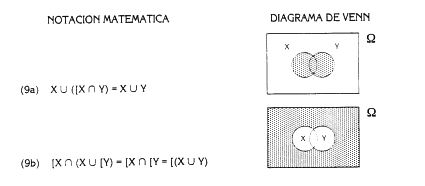
2.2 BASES MATEMATICAS La determinación cuantitativa de las frecuencias de los accidentes se basa en la teoría matemática de las probabilidades de la cual se hace una breve exposición. 2.2.1 Teoría de probabilidades Se define un experimento aleatorio como cualquier proceso de observaciones cuyos resultados son no determinísticos, es decir, que existe más de una posibilidad de resultado. Es el típico caso del lanzamiento de un dado. La totalidad de los resultados posibles de un experimento recibe el nombre de espacio muestral. Los resultados de un experimento se pueden considerar como elementos del espacio muestral que puede ser discreto (número finito o infinito numerable de elementos) o contínuo. Se denomina suceso al resultado o conjunto de resultados de un experimento que, por tanto, puede definirse como un subconjunto determinado de un espacio muestral. La teoría de conjuntos permite llevar a cabo una serie de combinaciones sobre los conjuntos a través de tres operaciones: la unión (U), la intersección («) y la complementariedad ([A, notación de complementario de un conjunto A) de conjuntos. Se pueden definir los siguientes tipos de sucesos: Suceso cierto es aquel que ocurre siempre. El subconjunto asociado es el espacio muestral entero. Suceso imposible es aquel que nunca se produce como consecuencia de un experimento. El subconjunto asociado es el conjunto vacío. Sucesos idénticos son sucesos que se producen o no simultáneamente para cada observación del experimento. Suceso complementario ([A) o contrario de un suceso determinado, es el que ocurre siempre y cuando no ocurra el suceso y viceversa. Sucesos incompatibles, mutuamente independientes o también excluyentes, son sucesos que no pueden ocurrir al mismo tiempo. Suceso dependiente o condicionado (A/B), es el suceso (A) cuya ocurrencia viene condicionada por la ocurrencia de otro suceso (B). Se dice que S, un subconjunto de sucesos del espacio muestral, tiene una estructura de álgebra de Boole con respecto de las operaciones de unión, intersección y complementariedad, cuando el espacio muestral es finito. Las propiedades que caracterizan un álgebra de Boole son las reseñadas en la tabla 2.1 (según Fault Tree Handbook 1986), donde se indican también la representación de los diagramas de Venn.
Se considera que una álgebra de sucesos es una sigma-álgebra cuando el espacio muestral es además contable. Definición de la función probabilidad En un experimento aleatorio se pueden obtener una serie de resultados: A, B,.... Z. Se repite N veces el experimento y se obtiene n veces el resultado A. La frecuencia relativa del suceso «obtención de A» es n/N. Se define la probabilidad de obtención del resultado A como:
Esta definición empírica de la probabilidad, conocida como interpretación frecuencial de la probabilidad, se formaliza matemáticamente de la siguiente manera: Dado un espacio muestral finito Ω y un suceso A de Ω, se define la probabilidad de A, P(A), como el valor de la función de probabilidad P que cumple los siguientes axiomas:
Como consecuencia de esta definición se cumplen las siguientes propiedades:
siendo [A el suceso complementario de A, tal como se dijo anteriormente Los teoremas fundamentales de la función de probabilidad son los siguientes: Teorema de las probabilidades totales o de Poincaré Permite calcular la probabilidad de la unión de N sucesos Ai:
donde, Ai es uno de los N sucesos considerados y p(Ai) su probabilidad. El primer sumando representa la suma de las probabilidades de los sucesos considerados y los restantes términos la resta/suma de las intersecciones de dos a dos, tres a tres, etc., de los sucesos. En el caso particular de dos sucesos, la expresión se simplifica a: P(A U B) = P(A) + P(B) - P(A ∩ B) Teorema de las probabilidades compuestas Este teorema permite calcular la probabilidad de sucesos condicionados. Cualquiera que sean los sucesos A y B del espacio muestral: P(A ∩ B) = P(A) . P(B/A) si P(A) # 0 (1) P(A ∩ B) = P(B) . P(A/B) si P(B) # 0 (2) donde p(A/B) representa la probabilidad de que, habiendo ocurrido el suceso B, se produzca el suceso A En el caso particular de sucesos independientes se verifica: P(A ∩ B) = P(A) . P(B) Teorema de Bayes Este teorema amplia el anterior proporcionando una expresión más general que permite calcular la probabilidad de que ocurra un determinado suceso Ai (entre sucesos excluyentes que definen un espacio muestral), condicionado por la ocurrencia de un suceso B, que ocurre siempre y cuando se produce al menos uno de estos sucesos Ai. Este teorema también se denomina el teorema de la probabilidad de las causas, porque conocidas las probabilidades p(Ai) -o probabilidades a priori-, permite calcular las probabilidades p(Ai/B) o probabilidades a posteriori. Para cualquier conjunto de n sucesos mutuamente excluyentes Ai que definen el espacio muestra�, se cumple:
La probabilidad de que se produzca B es: p(B) = p(A1∩ B) + p(A2 ∩ B) +� aplicando el teorema de las probabilidades compuestas: p(B) = p(A1) . p(B/ A1) + p(A2) . p(B/ A2) +� Es decir:
Por otra parte, partiendo del teorema citado e igualando los dos términos de la derecha de las expresiones (1) y (2): p(Ai) . p(B/Ai) = p(B) . p(Ai/B) De donde:
Sustituyendo p(B) por el valor obtenido en (3) se obtiene la probabilidad de que ocurra uno de los suceso excluyentes Ai, dado que se ha producido el suceso B es:
Esta expresión deducida para el caso descrito, tiene su equivalente para funciones de distribución continuas. Bajo esta forma, este teorema encuentra una de sus aplicaciones en el caso de los bancos de datos de fiabilidad. Partiendo de una distribución estadística a priori genérica para la fiabilidad de un determinado tipo de componente, se puede obtener su distribución estadística a posteriori, teniendo en cuenta los resultados de unas pocas pruebas sobre una muestra de componentes específicos. Como ejemplos de esta aplicación se podrían citar:
|
||||||